Excel MID関数:文字列抽出の基本と応用テクニック
ExcelのMID関数は、文字列から特定の位置と長さに基づいて部分文字列を抽出するための強力なツールです。この関数は、データの整理や分析、文字列の加工など、さまざまな場面で活用できます。本記事では、MID関数の基本的な使い方から、応用的なテクニックまでを詳しく解説します。特に、テキストの任意の位置から文字列を抽出する方法や、他の関数との組み合わせによる複雑な文字列処理についても触れます。また、MID関数の注意点や、他の文字列抽出関数との比較も紹介します。Excelを活用する上で、MID関数は非常に有用なスキルとなることでしょう。
MID関数の基本
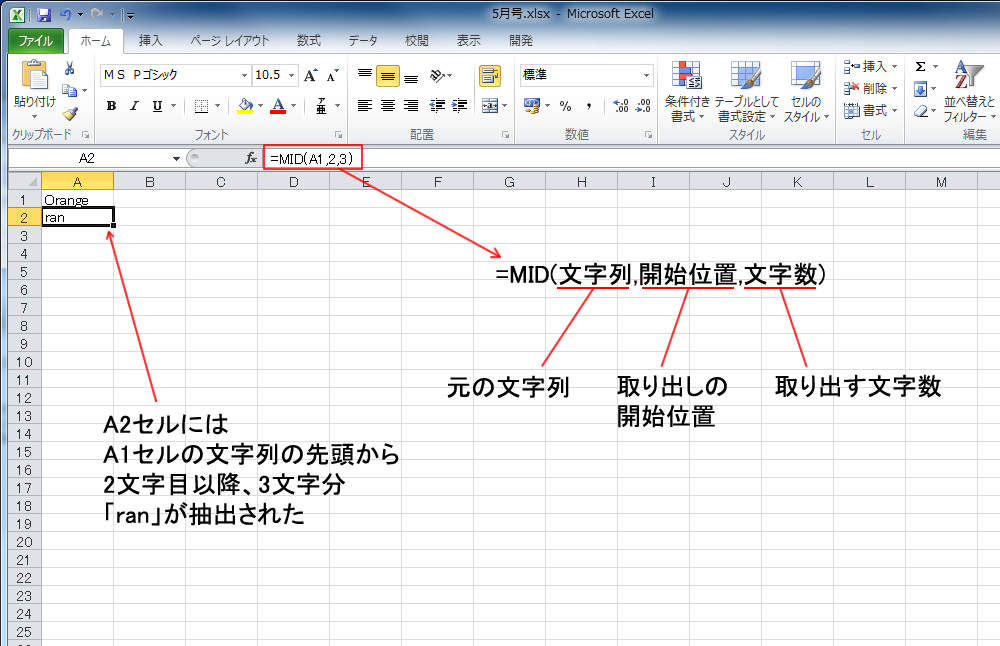
MID関数は、Excelで文字列から任意の位置から任意の長さの文字列を抽出するために使用される関数です。この関数は、データの整理や分析に非常に役立ちます。MID関数の基本的な構文は、MID(テキスト, 開始位置, 文字数)です。ここでのテキストは、文字列が含まれるセルを指し、開始位置は文字列のどの位置から抽出を開始するかを指定し、文字数はどのくらいの長さの文字列を抽出するかを指定します。
例えば、A1セルに「Hello World」があり、7文字目から5文字を抽出したい場合、MID(A1, 7, 5)と入力すると、「World」が得られます。このように、MID関数は特定の位置から任意の長さの文字列を効果的に抽出できます。
MID関数の注意点として、開始位置が文字列の長さより大きい場合や、文字数が0または負の数の場合、空の文字列が返されます。また、開始位置が1より小さい場合、VALUE!エラーが返されます。これらの点に注意しながら使用することで、より正確な文字列操作が可能になります。
MID関数の引数
MID関数は、文字列から特定の位置から任意の長さの文字列を抽出するために使用されます。この関数は、データを整理したり分析したりする際によく活用されます。MID関数の基本的な構文は、MID(テキスト, 開始位置, 文字数)です。ここで、「テキスト」は抽出したい文字列が含まれているセルを指定します。「開始位置」は、抽出を開始する位置を指定します。「文字数」は、抽出する文字の数を指定します。
例えば、A1セルに「Hello World」があり、7文字目から5文字を抽出したい場合、MID(A1, 7, 5)と入力すると、「World」が得られます。このように、MID関数は非常に柔軟で、文字列の任意の部分を正確に抽出できます。
MID関数の応用例としては、郵便番号、氏名、電話番号の抽出などが挙げられます。例えば、電話番号「090-1234-5678」から「1234」を抽出するには、MID(A1, 5, 4)を使用します。また、MID関数と他の関数(LEN関数やFIND関数など)を組み合わせることで、より複雑な文字列処理が可能になります。例えば、メールアドレス「example@example.com」からドメイン部分「example.com」を抽出するには、MID(A1, FIND("@", A1) + 1, LEN(A1) - FIND("@", A1))を使用します。
注意点として、開始位置が文字列の長さより大きい場合や文字数が0または負の数の場合、空の文字列が返されます。また、開始位置が1より小さい場合、VALUE!エラーが返されます。これらの点に注意しながら、MID関数を活用することで、効率的なデータ処理が可能になります。
例:文字列の抽出
MID関数は、Excelで文字列から任意の位置から任意の長さの文字列を抽出するために使用されます。この関数は、データの整理や分析に非常に役立ち、様々な場面で活用されています。例えば、A1セルに「Hello World」という文字列がある場合、7文字目から5文字を抽出したいとします。この場合、MID関数を使用して、MID(A1, 7, 5)と入力することで、「World」という文字列を取得できます。
応用例としては、郵便番号や氏名、電話番号の抽出などがあります。例えば、電話番号の国番号を削除して本体の番号だけを抽出したい場合、MID関数を用いることで簡単に実現できます。また、MID関数と他の関数(LEN関数やFIND関数など)を組み合わせることで、より複雑な文字列処理も可能になります。メールアドレスからドメイン部分を抽出する際には、MID関数とFIND関数を組み合わせて使用することで、効率的に目的の文字列を取得できます。
注意点として、MID関数で指定する開始位置が文字列の長さより大きい場合や、文字数が0または負の数の場合、空の文字列が返されます。また、開始位置が1より小さい場合は、VALUE!エラーが返されます。これらの点を確認しながら、適切にMID関数を使用することで、より正確な文字列操作が可能になります。
応用例:郵便番号の抽出
MID関数は、文字列から指定した位置と長さの部分文字列を抽出するためのExcel関数です。この関数は、データの整理や分析に特に有用です。例えば、郵便番号の抽出では、MID関数の応用が大いに活きる場面があります。日本では、郵便番号は7桁の数字で構成され、通常「-」で区切られます(例:123-4567)。この形式の郵便番号から、最初の3桁と最後の4桁を個別に抽出する必要がある場合、MID関数を用いて効率的に処理できます。
例えば、A1セルに「123-4567」という郵便番号が入力されているとします。最初の3桁を抽出するには、MID(A1, 1, 3)と入力します。これにより、「123」が得られます。同様に、最後の4桁を抽出するには、MID(A1, 5, 4)と入力します。これにより、「4567」が得られます。このように、MID関数を使用することで、特定の位置から任意の長さの文字列を簡単に抽出できます。
さらに、郵便番号の形式が一貫していない場合でも、MID関数と他の関数を組み合わせることで対応できます。例えば、郵便番号の「-」が存在しない場合や、位置が異なる場合でも、FIND関数とLEN関数を併用することで、正確に抽出することが可能です。具体的には、FIND関数で「-」の位置を特定し、その位置を基準にMID関数を使用することで、目的の部分文字列を抽出できます。このような組み合わせは、データの多様性に対応するための重要なテクニックです。
応用例:メールアドレスからドメインの抽出
メールアドレスからドメインを抽出する場合、MID関数とFIND関数を組み合わせて使用すると効果的です。例えば、A1セルに「example@domain.com」というメールアドレスが入力されているとします。この場合、ドメイン部分を抽出するために、最初に「@」の位置を特定する必要があります。FIND関数を使用して「@」の位置を取得し、その位置から1文字後からドメインの文字数を指定することで、MID関数でドメインを抽出できます。
具体的には、FIND関数で「@」の位置を取得し、その位置に1を足した値をMID関数の開始位置として指定します。さらに、ドメインの長さを計算するために、メールアドレス全体の長さ(LEN関数で取得)から「@」の位置を引いた値を使用します。このようにして、MID関数を用いてドメイン部分を正確に抽出することができます。例えば、FIND("@", A1) + 1 で「@」の位置を特定し、LEN(A1) - FIND("@", A1) でドメインの長さを計算します。最終的な式は、MID(A1, FIND("@", A1) + 1, LEN(A1) - FIND("@", A1)) となり、「domain.com」が得られます。
この方法は、メールアドレスの形式が一定でない場合でも、柔軟に対応することができます。また、文字列操作の基本的なテクニックを組み合わせることで、より複雑な文字列処理も可能になります。例えば、ドメイン部分からサブドメインを除去する場合や、特定のドメインのみを抽出する場合など、様々な応用が考えられます。
注意点:エラーの回避
ExcelのMID関数を使用する際には、いくつかの注意点を理解することが重要です。まず、開始位置が文字列の長さより大きい場合、または文字数が0または負の数の場合、MID関数は空の文字列を返します。これは、指定した開始位置が文字列の範囲外であるため、または抽出する文字数が無効であるためです。例えば、A1セルに「Hello World」があり、MID(A1, 15, 5)と入力すると、空の文字列が返されます。
また、開始位置が1より小さい場合、VALUE!エラーが返されます。これは、開始位置が無効な値であるためです。例えば、MID(A1, 0, 5)やMID(A1, -1, 5)と入力すると、VALUE!エラーが表示されます。このようなエラーを回避するためには、開始位置が1以上であることを確認する必要があります。
さらに、文字列の長さを正確に把握するためには、LEN関数を使用すると便利です。LEN関数は、指定した文字列の文字数を返します。これにより、MID関数の開始位置や文字数を適切に設定することができます。例えば、A1セルに「Hello World」があり、その文字数を確認したい場合、LEN(A1)と入力すると11が返されます。この情報を基に、MID関数のパラメータを設定することで、エラーを回避できます。
最後に、複雑な文字列処理を行う際には、MID関数と他の関数を組み合わせて使用することが効果的です。例えば、メールアドレスからドメインを抽出するには、MID関数とFIND関数を組み合わせて使用します。FIND関数は、指定した文字列が最初に現れる位置を返します。これにより、MID関数の開始位置を正確に設定できます。
MID関数と他の関数の組み合わせ
MID関数は、Excelの文字列操作において非常に重要な役割を果たします。MID関数は、指定された開始位置から任意の長さの文字列を抽出するために使用されます。この関数は、データの整理や分析に欠かせないツールであり、様々な応用が可能です。例えば、郵便番号から都道府県コードを抽出したり、電話番号から地域コードを分離したりすることができます。
MID関数を単独で使用するだけでなく、他のExcel関数と組み合わせることで、より高度な文字列処理が可能になります。特に、FIND関数やLEN関数との組み合わせは、非常に頻繁に使用されます。FIND関数は、指定した文字列がテキスト内にある位置を返します。これにより、MID関数の開始位置を動的に決定することができます。一方、LEN関数は、テキストの長さを返します。これを利用して、MID関数の抽出文字数を調整できます。
例えば、メールアドレスからユーザー名とドメインを分離したい場合、MID関数とFIND関数を組み合わせて使用します。まず、FIND関数で「@」の位置を特定し、その位置に基づいてMID関数を使用してユーザー名とドメインをそれぞれ抽出します。同様に、LEN関数とMID関数を組み合わせて、文字列の末尾から特定の文字数を抽出することもできます。これらの組み合わせは、複雑な文字列処理をシンプルに実現するための強力な手段です。
MID関数とLEFT/RIGHT関数の比較
MID関数は、Excelで文字列から任意の位置から任意の長さの文字列を抽出するために使用される関数です。LEFT関数とRIGHT関数は、それぞれ文字列の最初から指定した数の文字を抽出したり、最後から指定した数の文字を抽出したりするために使用されます。しかし、MID関数はより柔軟な文字列操作が可能です。
例えば、LEFT関数は文字列の最初から指定した数の文字を抽出します。A1セルに「Hello World」があり、最初の5文字を抽出したい場合、LEFT(A1, 5)と入力すると「Hello」が得られます。一方、RIGHT関数は文字列の最後から指定した数の文字を抽出します。同じ「Hello World」から最後の6文字を抽出したい場合、RIGHT(A1, 6)と入力すると「World」が得られます。
MID関数は、文字列の任意の位置から文字列を抽出できます。A1セルに「Hello World」があり、7文字目から5文字を抽出したい場合、MID(A1, 7, 5)と入力すると「World」が得られます。このように、MID関数は文字列の任意の位置から始めて、任意の長さの文字列を抽出できるため、DATAの整理や分析に非常に役立ちます。
さらに、MID関数と他の関数を組み合わせることで、より複雑な文字列処理が可能になります。例えば、メールアドレスからドメイン部分を抽出する場合、MID関数とFIND関数を組み合わせて使用します。A1セルに「example@example.com」があり、ドメイン部分を抽出したい場合、MID(A1, FIND("@", A1) + 1, LEN(A1) - FIND("@", A1))と入力すると「example.com」が得られます。このように、MID関数は柔軟性と多機能性を兼ね備えた強力なツールです。
MID関数とMIDB関数の違い
ExcelのMID関数とMIDB関数は、どちらも文字列から特定の部分を抽出するための関数ですが、その処理方法に違いがあります。MID関数は、文字列から任意の位置から任意の長さの文字列を抽出します。この関数の基本的な構文は MID(テキスト, 開始位置, 文字数) で、それぞれの引数は文字列の開始位置と抽出する文字数を指定します。一方、MIDB関数は、文字列から任意の位置から任意のバイト数の文字列を抽出します。MIDB関数の基本的な構文は MIDB(テキスト, 開始バイト, バイト数) です。
主要な違いは、文字のカウント方法にあります。MID関数では、各文字が1文字としてカウントされます。つまり、1文字につき1として扱われます。これに対して、MIDB関数では、各文字がバイト数でカウントされます。日本語やその他のマルチバイト文字を使用する場合、1文字が2バイトまたはそれ以上のバイトを占めることがあり、MIDB関数はそのバイト数を正確にカウントします。この違いにより、MIDB関数は特にマルチバイト文字を扱う際や、文字列のバイト数を正確に制御する必要がある場合に有用です。
例えば、A1セルに「こんにちは、世界」(6文字)とあり、3文字目から2文字を抽出したい場合、MID関数では MID(A1, 3, 2) と入力することで「にち」が得られます。同じ文字列から3バイト目から4バイトを抽出したい場合、MIDB関数では MIDB(A1, 3, 4) と入力することで「に」が得られます。このように、MID関数とMIDB関数は、文字列の扱い方や用途によって適切に選択されるべきです。
まとめ
ExcelのMID関数は、文字列から任意の位置と長さの部分文字列を抽出するための強力なツールです。この関数は、テキストデータの整理や分析に広く使用されており、データ処理の効率を大幅に向上させることが可能です。MID関数の基本的な使い方は、3つの引数:テキスト、開始位置、文字数を指定することで、任意の文字列から必要な部分を抽出できます。例えば、A1セルに「Hello World」という文字列があり、7文字目から5文字を抽出したい場合、MID(A1, 7, 5)と入力すると、「World」という文字列が得られます。
応用例としては、郵便番号や電話番号の特定の部分を抽出する、氏名の姓と名を分ける、メールアドレスからドメイン部分を抽出するなど、様々な場面で活用できます。これらの応用例では、MID関数を単独で使用するだけでなく、LEN関数やFIND関数と組み合わせることで、より複雑な文字列処理を実現できます。例えば、メールアドレス「example@example.com」からドメイン部分を抽出するには、MID(A1, FIND("@", A1) + 1, LEN(A1) - FIND("@", A1))と入力することで、「example.com」が得られます。
MID関数の注意点として、開始位置が文字列の長さより大きい場合や、文字数が0または負の数の場合、空の文字列が返されます。また、開始位置が1より小さい場合、VALUE!エラーが返されます。これらのエラーを避けるためには、適切な引数を指定することが重要です。
他の文字列抽出関数であるLEFT関数やRIGHT関数と比較して、MID関数は任意の位置から文字列を抽出できるため、より柔軟な文字列操作が可能です。さらに、MID関数とMIDB関数の主な違いは、文字のカウント方法にあります。MID関数は各文字を1文字としてカウントし、MIDB関数は各文字をバイト数でカウントします。これにより、異なる文字コードの文字列に対して適切な処理を行うことができます。
よくある質問
MID関数の基本的な使い方は?
MID関数は、指定した位置から文字列を抽出するための関数です。基本的な構文は MID(テキスト, 開始位置, 文字数) で、テキスト には文字列、開始位置 には抽出を開始する位置、文字数 には抽出する文字数を指定します。例えば、セル A1 に "Hello, World!" という文字列があり、5文字目から5文字を抽出したい場合、 MID(A1, 5, 5) と入力すると "o, Wo" が結果として表示されます。この関数は、特定の部分文字列の抽出 に非常に役立ち、データの整理や加工に欠かせないツールとなっています。
MID関数と他の関数を組み合わせて使う方法は?
MID関数は単独で使用するだけでなく、他の関数と組み合わせることでより複雑な文字列操作が可能です。例えば、FIND関数 と組み合わせて特定の文字や文字列の位置を見つけることができます。FIND関数の構文は FIND(検索テキスト, 内部テキスト, [開始位置]) で、検索テキストが内部テキストの何文字目に存在するかを返します。この位置情報をMID関数の 開始位置 に使用することで、動的な文字列抽出 が可能になります。また、LEN関数 と組み合わせることで、文字列の長さを取得し、その情報を基に文字列の後半部分だけを抽出することもできます。これらの関数の組み合わせは、高度な文字列処理 に欠かせないテクニックです。
MID関数で文字列の特定部分を置換する方法は?
MID関数自体は文字列の置換を行う機能はありませんが、REPLACE関数 と組み合わせることで、特定部分の文字列を置換することができます。REPLACE関数の構文は REPLACE(元のテキスト, 開始位置, 文字数, 新しいテキスト) で、元のテキスト から 開始位置 から 文字数 の文字を 新しいテキスト に置換します。例えば、セル A1 に "Hello, World!" という文字列があり、"World" を "Excel" に置換したい場合、 REPLACE(A1, 8, 5, "Excel") と入力すると "Hello, Excel!" が結果として表示されます。MID関数で 特定部分の位置と長さ を取得し、それをREPLACE関数に渡すことで、動的な置換処理 を行うことができます。
MID関数で文字列の先頭や末尾の部分を抽出する方法は?
MID関数を使用して文字列の先頭や末尾の部分を抽出するには、いくつかの方法があります。先頭部分の抽出 には、MID(テキスト, 1, 文字数) の形式を使用します。例えば、セル A1 に "Hello, World!" という文字列があり、先頭から5文字を抽出したい場合、 MID(A1, 1, 5) と入力すると "Hello" が結果として表示されます。末尾部分の抽出 には、LEN関数 と組み合わせて使用します。MID(テキスト, LEN(テキスト) - (抽出したい文字数 - 1), 抽出したい文字数) の形式で、文字列の末尾から指定した文字数を抽出できます。例えば、セル A1 に "Hello, World!" という文字列があり、末尾から7文字を抽出したい場合、 MID(A1, LEN(A1) - (7 - 1), 7) と入力すると "World!" が結果として表示されます。これらの方法は、文字列の特定部分の抽出 に非常に効果的です。
Deja una respuesta
Lo siento, debes estar conectado para publicar un comentario.
関連ブログ記事